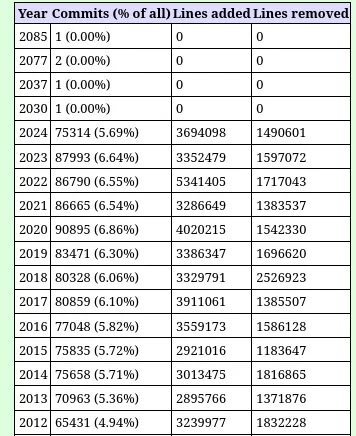
Because “number of commits” is such a relevant metric (for reference 85% of the commits resulted in 110% of added lines compared to 2023).
Are people too lazy to talk about actual features and stuff added, so they compare some arbitrary number because that’s a stat easily pulled from the data?
PS: Nice to see the comments talking about “woke” developers… Guess the culture war brain rot really spreads everywhere 🤮
This is from the article:
But the commit count is just one metric and this year saw 3,694,098 new lines of code and 1,490,601 lines of code removed. That’s comparable to prior years with last year seeing 3.3 million new lines and 1.59 million lines removed… Down from the 5.3 million new lines in 2022 but for 2021 was also in the 3.2 million new line range. So in terms of code activity, 2024 was largely similar to prior years for the Linux kernel, just with far fewer commits.
Yes, I read the article (that’s were my “number of lines” come from…). But does including this in the article make a shitty article any better?
It’s basically “Linux kernel hits record low” (also the title) followed by “but by other metrics it looks different” and then… nothing. No actual analysis, no context. Just randomly presenting numbers (and even admitting their headline metric isn’t worth much) and pretending that’s an article.
That’s stupidly lazy…
Starting a conversation with Statistics has long been a sign being too lazy to make a mechanism to include in the Hypothesis. It has extended to, giving the stats and making the theory without caring about adding a mechanism to the hypothesis.
That is what leads to “stats is evil”.Because, on top of the number of lines, it will also matter what kind of code is there in the line.
One can easily fill a 100 lines of code, hardcoding a lookup table with minimal logic in it. At the same time, a few lines of changed code might make a big difference. Then, if multiple significant changes are done to a single feature, they all might be given in a single commit, making the number of commits very low, while having the changes spread across several different features, might require separate commits, increasing the count.I’ll take these stats as a fun little number, usable to make some good looking graphs, but that’s all.