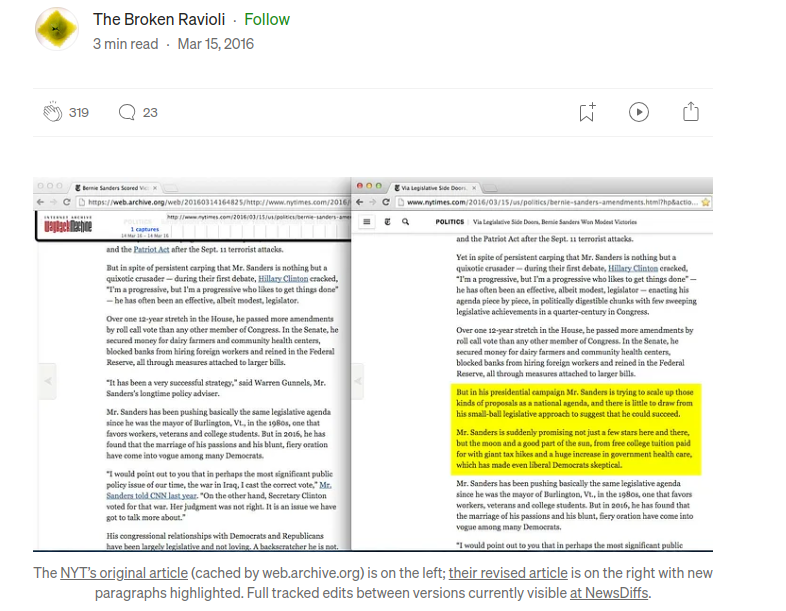
Walled Culture has already written about the two–pronged attack by the copyright industry against the Internet Archive, which was founded by Brewster Kahle, whose Kahle/Austin Foundation supports this blog. The Intercept has an interesting article that reveals another reason why some newspaper publishers are not great fans of the site: The New York Times tried …

I hate to sound like such a darn boot licker, but if NYT doesn’t want Archive crawler on thier domain, what reason can you possibly come up with (legitimately, not based on your feelings) as to why they should have to allow this?
Private business gets to do private business things, nothing to see here other than that tbh.
Honestly as NYT subscriber I really doubt that people actually read NYT through archive or at least most of the archive reader wouldn’t convert anyway. To me it seems like a bad sign of them trying to hide something. Archive is a public way to track website changes which is very valuable for validating journalism.
In general NYT is trying to have their content public and take advantage of indexing but also private for selling subscriptions. It’s a bit of a paradox that really diminishes their position here.
^ This sort of bullshit argument is why we never should’ve stopped requiring a copy of everything to be sent to the Library of Congress in order to earn copyright protection.
Those “private businesses” are treating a privilege granted by Congress as an entitlement. They do not “get” to do that.